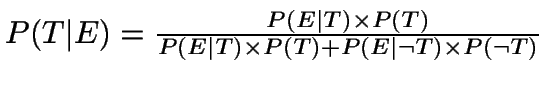
Sources of noise in data-taking: We may have to contend with purely instrumental noise sources - grain statistics in photography, amplifier noise in photomultipliers or CCDs, thermal noise in cooled detectors, etc. The most fundamental limit is that set by photon noise. Photons arrive randomly, with a certain mean rate set by the radiation intensity and wavelength. Always keep in mind that the photon noise may include a contribution from sources that are a nuisance, such as airglow or scattered sun- or moonlight, and that the numbers of photons in calculations must include this "background". Also note that a form of noise can be introduced in digitizing a signal (roundoff or truncation) or in further processing, for example in use of calibration data less accurate than the desired results.
It can be important to watch the sources of error for a given measurement. In succeeding steps, errors may accumulate. Statistically independent errors add in quadrature. To track this, you may need to carry an error term through all steps of a calculation, or simply add all the relative errors in quadrature. Doing this before carrying out a series of measurements can be very instructive.
Consider a process (such as detection of a photon in all but the highest radiation densities) with constant probability per unit time; that is, the probability of detecting a photon in dt is λdt for dt infinitesimal, and the expected number detected in finite time interval ΔT is then λ ΔT. What is the expected distribution of the number actually detected in various statistically independent time intervals, or experimental trials?
This was worked out by Poisson in 1831, and later by Gossett (writing as "Student" due to employment restrictions at the Guinness Brewery). If we define Wn(t) as the probability of seeing exactly n events in a time interval T, we have
| Probability of n+1 events in time t = Wn+1(t) |
| Probability of 0 events in time dt = 1 - λdt |
| Probability of n events in time t = Wn(t) |
| Probability of 1 event in time dt = λ dt |
| Probability of n-1 events in time t = Wn-1(t) |
| Probability of 2 events in time dt = (λ dt)2 |
For large n, the probability distribution approaches the normal or Gaussian distribution
| P(n > M+ σ) = 0.16 |
| P(n > M+2 σ) = 0.023 |
| P(n > M+3 σ) = 0.0013 |
Gaussians have many useful properties. For example, the convolution of two Gaussians of different σ is another Gaussian with σ2 = σ12 + σ22. The Fourier transform of a Gaussian is another Gaussian. Instrumental profiles are frequently Gaussian enough that this analytically useful form is used as a fitting function with or without explicit motivation.
The transition from small-number Poisson statistics to a Gaussian is one application of the central limit theorem. This states that for an arbitrary distribution f(x),if one repeatedly measures the mean of f from sufficiently large numbers of trials, the measured means will themselves obey a normal distribution. This enters almost intuitively into experimental and observational design.
There are several commonly used statistics for a distribution, expressing either some measure of the zero point or width. These include mean, median, and mode for the zero point, and various moments for the width (and more details). The mean (or average) is defined by Σ x f(x) dx where f(x) is the normalized distribution. The mean may be strongly affected by (possibly spurious) outlying values, so that for some applications the median or mode may be preferable. As an example, say we want to know the sky brightness in some image, where the mean may be contaminated by faint stars, cosmic-ray events, etc. Here, the mode will be a better estimate of what we're after, though still not perfect - to do it right, one would need to understand the distributions of the contaminating processes. The more you know a priori, the better you can do...
We are often interested in what we can learn from data sets via statistical tests. As examples, what is the average luminosity of RR Lyrae stars, or the average X-ray-to-visual ratio for solar type stars? Different kinds of tests are in order, depending on whether there is a physically motivated model to test or parameter to measure. Sometimes, we can only ask whether a data set is consistent with another one or not, or whether two kinds of objects are the same or different. These reflect parametric and nonparametric statistics. Further broadening the field, one must sometimes deal with data sets (such as surveys) with a fixed and high detection threshold, where you wish to derive a mean flux for sets of objects where the positions is known but none is detected individually.
Parametric statistics may include model fitting and parameter estimation. Linear regression is one example. Other commonly used techniques include least-squares function fitting and χ2 minimization.
Least-squares fitting, in its linear variety, is used when there is reason to believe that the data represent points of the form yi = Σ an fn(xi). A special case is fitting a line, yi = a0 + a1 xi . The usual derivation takes all the scatter in data as along the y axis; more complicated variants exist in the case of substantial errors in both variables. The goodness-of-fit criterion here is that the best fit is defined to be the one for which the sum Σ(y' - yi)2 is minimized, where y' is the value predicted for a given set of coefficients an. It can be shown that minimizing the squared residuals from a given functional fit is yields sets of normal equations from the given data of the following form:
Another widely-useful fitting technique, especially important for data sets where the errors may not be normally distributed or differ widely among data points, is χ2 fitting. Here, one finds the values of parameters for some fitting function that minimizes the quantity χ2 = Σ (y' - yi)/σ2 for which it is important that one have an accurate assessment of σ (be honest, now!). Not only does this give parameter estimates, but also tells how well they represent the data. For a good fit, the reduced χ2 (which is the value above divided by n-p, the number of data values minus the number of parameter values determined in the fit) should be close to 1. This approach can also be used to tell whether specific components of a proposed model are significant in a statistical sense. Mapping χ2 as a function of the parameters allows study of the allowed parameter space and any correlation of errors in their estimates. There can be subtleties in application when the fitting function has most of its weight in a small part of the data space, or for small-number statistics (n < 5 or so gives biased results). These pitfalls, and limits on what reduced χ2 means for complex fitting functions are discussed in this paper
Often, either the formulation of a problem or the nature of the data do not admit a parametric approach. This happens when we want to ask, "Are these two samples drawn from the same parent population?", or when there are upper or lower limits as well as genuine measurements. In the first case, one may use comparisons of ranked lists or the Kolmogorov-Smirnov test, which compares cumulative distribution functions of two samples or a sample and a model. The maximum difference between the CDFs for a given sample size is the critical statistic. In the second case, there is a body of approaches known as survival analysis; Feigelson and collaborators have brought this work to astronomers' attention, and produced Fortran routines for their implementation. See, for example, Isobe et al 1990, ApJ 364, 104; Babu and Feigelson 1992, Commun. Statist. Comput. Simul. 22, 533; and Feigelson and Babu 1992, ApJ 397, 55
Statistical sleaze - when do you reject points, and when do you "accept" a hypothesis?
In contrast to the more usually encountered frequentist ap`proach to statistical analysis, which deals in essence with values that would be obtained from many runs of an experiment or increases in observed sample size, there is often a gain from considering the Bayesian approach, which centers on how evidence affects our degree of confidence in a hypothesis (often itself based on previous evidence). Here, the likelihood of a hypothesis given a particular set of data (evidence E) and model (theory T) is evaluated using Bayes' theorem:
As noted in, for example, Statistics in Theory and Practice (R. Lupton, Princeton 1993) this is not at all controversial. This approach is explicit about prior probabilities (or priors for various outcomes. In those cases that we really do understand this well, this can be a powerful The result can be inverted to yield maximum-likelihood estimates of parameters. As more and more data are available, Bayesian estimates often approach "classical" estimates, since the prior is less relevant when large amounts of data exist.
Some introductions to Bayesian reasoning:
In hypothesis testing, we distinguish two kinds of errors - Type I (false positive), and Type II (false negative). These may have very different impacts on one's conclusions.
This ss a good place to caution about the cogitive biases that the human brain seems to be universally susceptible to - so strongly that in places where it is a matter of life or death, analysts still need to be retaught how to recognize them regularly. These include confirmation bias, collecting nondiscriminatory evidence, and inappropriate weighting of evidence based on irrelevant factors.
Some good introductions to cognitive biases:
Last changes: 1/2014 © 2000-2014/A>